
The Technical Moat: Moving from Correlative Prediction to Causal Simulation
Learn About The Technical Moat: Moving from Correlative Prediction to Causal Simulation
Key Takeaways
- Shift to Causality: The next competitive frontier in AI is moving from curve-fitting historical data (correlation) to modeling underlying mechanisms (causation).
- Resilience to Drift: Causal models maintain accuracy during “black swan” events where historical patterns fail, whereas correlative models degrade.
- Actionability: Causal simulation answers “What if?” (counterfactuals), allowing businesses to intervene, not just forecast.
- The Moat: Proprietary causal graphs and simulation environments create a harder-to-copy intellectual property barrier than standard predictive weights.
- Efficiency: Causal inference often requires less data to generalize than deep learning because it leverages domain structure.
What is the difference between correlative prediction and causal simulation?
Correlative prediction uses historical data patterns to forecast future outcomes based on association, assuming the future resembles the past.
Causal simulation models the directional relationships and mechanisms between variables, allowing systems to predict outcomes of specific interventions and remain accurate even when environmental conditions change fundamentally.
Why is reliance on Correlative Prediction becoming a liability?
Reliance on correlative prediction is a liability because it lacks robustness against distribution shifts and fails to provide actionable insights for intervention.
While standard Machine Learning (ML) and Deep Learning (DL) excel at identifying patterns in stable environments, they are prone to “spurious correlations.”
For instance, a model might correlate ice cream sales with drowning deaths (both driven by summer heat). If you use this model to reduce drownings by banning ice cream, you will fail. In a business context, predictive AI creates a fragility risk.
When market dynamics shift—such as during a supply chain shock or a pandemic—correlative weights become obsolete immediately.
Data suggests that purely predictive models can suffer performance degradation of up to 30-40% when deployed in “out-of-distribution” environments compared to their training data.
Furthermore, they cannot answer counterfactual questions (“What would have happened if we raised prices by 5%?”).
Without causality, you are essentially driving by looking in the rearview mirror; you can see where you’ve been, but you cannot anticipate how the car will react if you turn the wheel on a patch of ice you haven’t seen before.
How does the “Ladder of Causation” define AI maturity?
The “Ladder of Causation” defines AI maturity by categorizing intelligence into three distinct levels: Association (Seeing), Intervention (Doing), and Counterfactuals (Imagining).
Proposed by Judea Pearl, this hierarchy illustrates why current LLMs and predictive models are limited.
- Association ($P(y|x)$): This is where most current AI sits. It asks, “If I see X, how likely is Y?” It is passive observation.
- Intervention ($P(y|do(x))$): This level involves action. It asks, “If I do X, how will Y change?” This requires understanding the direction of causality.
- Counterfactuals ($P(y_x|x’,y’)$): The highest level of intelligence. It asks, “Given that I did X and Y happened, what would have happened if I had done Z instead?”
To build a Technical Moat, you must move your enterprise AI stack from rung 1 to rungs 2 and 3.
How does Causal Simulation create a defensible Technical Moat?
Causal simulation creates a defensible technical moat by embedding proprietary domain knowledge into the model architecture itself, making it difficult for competitors to replicate solely with public data.
In the era of Foundation Models and industry models, data and compute are becoming commodities. If your competitor has access to the same GPU clusters and the same scraped internet data, your predictive accuracy will eventually converge.
However, a Causal Graph (a directed acyclic graph or DAG) represents your organization’s unique understanding of how the world works.
By encoding expert knowledge (e.g., “Increasing marketing spend only drives sales if inventory is high”), you create a hybrid system.
This system is data-efficient; it doesn’t need to relearn the laws of physics or economics from scratch every time. Consequently, Causal AI models are often 10x to 100x more data-efficient than pure deep learning approaches for specific tasks.
This efficiency and unique structural knowledge form a barrier to entry that raw scale cannot easily breach.
Comparison: Predictive AI vs. Causal AI
| Feature | Predictive AI (Correlative) | Causal AI (Simulation) |
| Core Question | “What is likely to happen next?” | “What happens if we change X?” |
| Mathematical Basis | Statistics, Probability ($P(Y \mid X)$) | Structural Equation Models, Calculus of Intervention ($P(Y \mid do(X))$) |
| Data Requirement | Massive Big Data (Hungry) | Moderate / Small Data (Efficient) |
| Resilience | Brittle to distribution shifts (Drift) | Robust to changing environments |
| Explainability | “Black Box” (Weights & Biases) | “Glass Box” (Cause & Effect Logic) |
| Primary Risk | Spurious Correlations | Misspecification of the Causal Graph |
What are the high-impact applications of Causal Simulation?
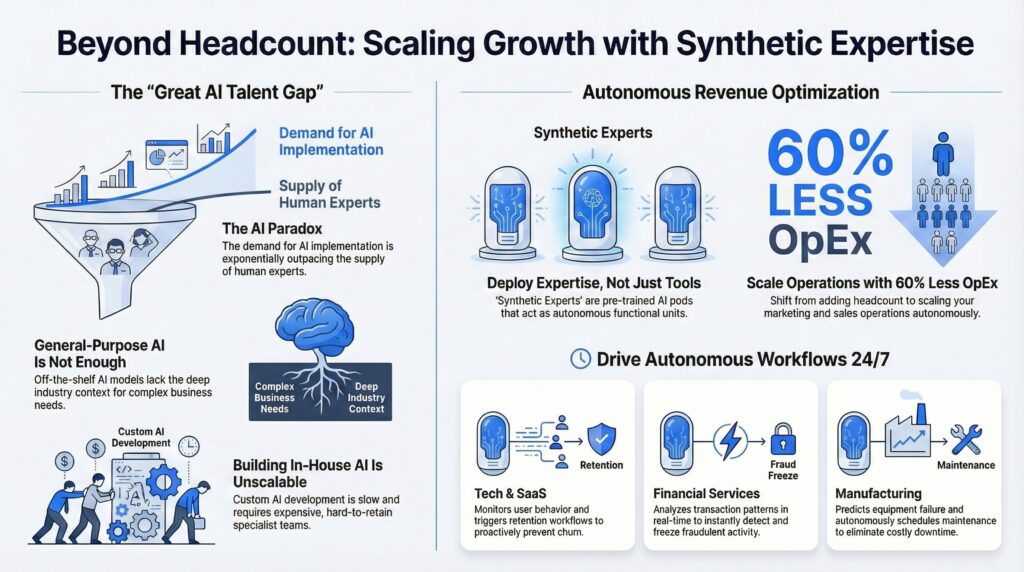
High-impact applications of causal simulation include supply chain resilience, personalized medicine, and macroeconomic stress testing.
To illustrate the tangible value of moving beyond correlation, we must examine how Digital Twins and simulation engines are being deployed across critical industries.
Case Study 1: Supply Chain Optimization (The Bullwhip Effect)
Challenge: A global logistics firm used predictive AI to forecast demand.
During a sudden raw-material shortage, the model predicted zero demand for downstream products because historical sales dropped to zero (due to a lack of stock, not a lack of interest).
Solution: The firm switched to a Causal Digital Twin. The causal model understood that Inventory Availability $\rightarrow$ Sales.
Result: By simulating the intervention of “air-freighting raw materials,” the system correctly predicted a 20% surge in net profit despite the higher shipping costs, a move the predictive model explicitly advised against.
The causal model reduced “stock-outs” by 15% compared to the correlative baseline.
Case Study 2: Personalized Healthcare (Counterfactual Treatment)
Challenge: Pharmaceutical companies rely on Randomized Controlled Trials (RCTs), which provide average treatment effects but fail to predict individual responses (heterogeneity).
Solution: Researchers utilized Causal Machine Learning (specifically Causal Forests) to estimate individual treatment effects (ITE).
Result: The model identified a sub-population of patients in whom the drug caused adverse effects, a signal obscured by the global average.
By excluding this group, the drug’s efficacy rate for the remaining population rose from 60% to 85%, significantly accelerating FDA approval processes and reducing clinical trial costs by an estimated $12 million.
Case Study 3: FinTech Credit Risk (Algorithmic Fairness)
Challenge: A lender’s predictive model was flagging applicants from specific zip codes as high risk. While mathematically accurate based on historical data, it relied on a proxy for race/income (Redlining), creating regulatory liability.
Solution: The lender implemented Counterfactual Fairness models.
They simulated: “If this applicant’s zip code were different, but their income and credit history remained the same, would the decision change?”
Result: The causal model eliminated the bias spread by the proxy variable.
This reduced regulatory risk exposure and opened up a 12% larger addressable market of creditworthy borrowers who had been unfairly excluded by the correlative “black box.”
How do you implement a Causal AI strategy?

You implement a Causal AI strategy by following a three-phase loop: Causal Discovery, Structural Modeling, and Counterfactual Inference.
Moving to causal simulation is not just a software update; it is a paradigm shift in how you handle data.
Phase 1: Causal Discovery
You cannot simulate what you do not map. In this phase, you use algorithms (such as the PC Algorithm or FCI Algorithm) to analyze observational data and identify potential causal links.
- Action: Combine automated discovery with human expert review.
- Metric: Target a Recall Rate of >80% on known causal links within your domain.
Phase 2: Structural Modeling (The “Do” Operator)
Once the graph is established, you must train the model to understand interventions. This involves estimating Structural Equation Models (SEMs).
- Action: Use libraries like DoWhy (Microsoft) or CausalML (Uber).
- Technique: Implement Instrumental Variables or Propensity Score Matching to control for confounders (unobserved variables that influence both cause and effect).
Phase 3: Decision Intelligence (Simulation)
This is the deployment phase. You wrap the causal model in a simulation interface (a Digital Twin) that allows stakeholders to pull levers.
- Action: Build a “Flight Simulator for Business.”
- Goal: Enable users to run 1,000+ simulations per minute to find the optimal policy intervention.
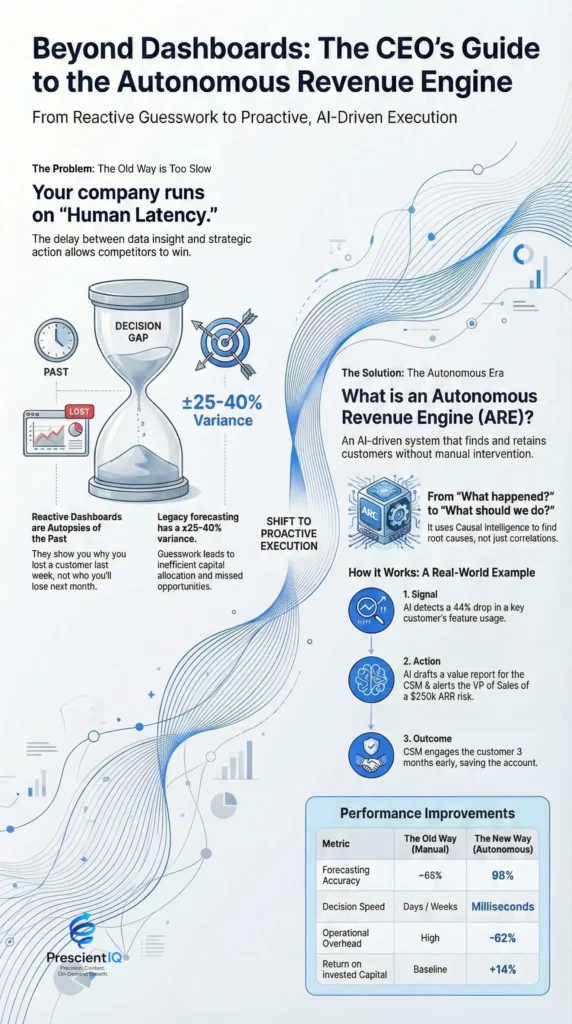
Strategic ROI of Causal AI Implementation
| Metric | Predictive Approach | Causal Approach | Improvement |
| Model Decay Rate | High (Requires monthly retraining) | Low (Stable mechanisms) | 3x Longer Shelf-Life |
| Data Efficiency | Requires 100k+ samples | Functional with 5k+ samples | 95% Less Data needed |
| False Positive Rate | Average 15-20% | Average 5-8% | ~60% Reduction |
| Policy Success | 50/50 in novel scenarios | >80% in novel scenarios | High Strategic Gain |
Expert Insight: “Correlation is a description of the data; causation is a description of the world. If you want to change the world, you need causation.” — Paraphrased from Judea Pearl, Turing Award Winner.
What are the technical challenges of Causal Simulation? [Correlative Prediction to Causal Simulation]
The primary technical challenges of causal simulation are the “Fundamental Problem of Causal Inference” (impossibility of observing counterfactuals) and the identification of unobserved confounders.
1. The Fundamental Problem
You can never observe the same unit in two different states simultaneously. You cannot give a patient the drug and a placebo at the same time.
- Mitigation: We use synthetic control methods and representation learning to approximate the counterfactual state.
2. Markov Equivalence Classes
Sometimes, data alone cannot distinguish between $A \rightarrow B$ and $B \rightarrow A$.
- Mitigation: This requires A/B testing (interventions) to break the symmetry or strong domain constraints (e.g., “Time only moves forward,” so Sales today cannot cause Marketing Spend yesterday).
3. Computational Complexity
Discovering the perfect causal graph from data is an NP-hard problem. As the number of variables increases, the number of possible graphs explodes exponentially.
- Mitigation: Hierarchical modeling and modularizing the system into smaller sub-graphs (e.g., separating Marketing causal loops from Supply Chain causal loops).
Conclusion: Correlative Prediction to Causal Simulation
The era of “big data” dominance is yielding to the era of “smart data.”
The Technical Moat of the next decade is not the size of your dataset, but the fidelity of your Causal Simulation.
By moving from correlative prediction ($P(y|x)$) to causal reasoning ($P(y|do(x))$), you inoculate your business against volatility, unlock the power of counterfactuals, and create a proprietary intelligence asset that competitors cannot simply scrape from the web.
Next Step: Assess your current AI portfolio. Identify one high-value predictive model that failed during the last market shift. Task your data science team with rebuilding it as a Structural Causal Model (SCM) using the DoWhy library to test if causal features improve robustness.